Statistical environment and programming language Overview of R and RStudio
As a programming language and statistical environment, “R” is primarily aimed at data scientists. At the same time, developers who analyze data and develop statistical programs or offer solutions in this area benefit. We give a first Overview.
Company on topic
 With RStudio, getting started with R is easier than without a suitable IDE. A desktop version is available for free.
With RStudio, getting started with R is easier than without a suitable IDE. A desktop version is available for free.
(Picture: Joos / RStudio)
The programming language and statistical environment R is available as open source. The free programming language R was created on the basis of the commercial statistical language “S”. R is modular and can be extended with packages.
In general, R is considered rather difficult to learn. Due to the modular design and the packages available with it, however, in most cases already finished packages can be integrated with RStudio and used productively. For almost all approaches that exist in statistics, ready-made R packages or at least code examples are also available.
Image gallery
Picture gallery with 6 pictures
Use R and RStudio in Windows, Linux and macOS
R can be installed in Windows, Linux and macOS. The download takes place directly on the R project page. Those who work with R also use a programming environment in most cases. When using R, RStudio is often set. The edition “RStudio Desktop” is available free of charge.
R has become a fixture in the field of data analysis and statistics. Therefore, for example, an interface has been integrated into Microsoft SQL Server, with which the data of databases on SQL servers can be accessed via R. It is therefore no longer necessary to export and import the data, R programs can read your data directly from the SQL server.
R and Microsoft SQL Server
Microsoft has provided a special R client for this purpose since SQL Server 2016. This allows users or developers to securely access the data of an SQL server directly from any computer using R scripts.
The R client optimizes the execution of the R scripts. For this purpose, several threads can be started at once. The R client transfers these to the SQL server and executes them directly on the server. Of course, this is much faster than executing individual tasks on the client and retrieving data from the server.
Install and use RStudio Desktop
Anyone who deals with R should start with RStudio. In the graphical interface it is easier to familiarize yourself with the environment. RStudio Desktop is available for free and is quickly ready for use in Windows, Linux and macOS. For learning R this is of course helpful.
“Global Options” is available via the menu item “Tools”. RStudio can be adapted to your own requirements. As part of the installation of RStudio does not include the installation of R itself. Therefore, R should be installed first before starting RStudio.
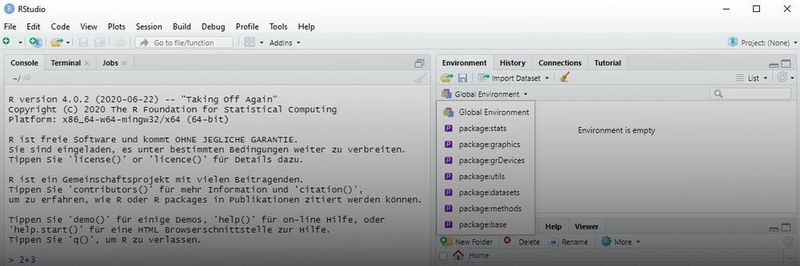
After starting RStudio, you will find the Console tab on the left. This is where the R commands to be executed in RStudio are entered. R can also be used to enter calculation tasks directly, for example “2+3”, “exp(1)” or “pi”.
In the upper right area, on the “Environment” tab, you can see the set variables as well as defined data sets and functions. By clicking on “Global Environment” a drop-down menu appears. Here you can see the packages that have been loaded. “History” shows the most recently executed R commands when the console has been deleted.
Further menu items can be seen at the bottom right. Here, “Files” can be used to manage the files that are used for the respective R project. The directory you are currently in can be displayed in the console with “getwd ()”. The directory can be changed with:
set(<Verzeichnis>)
Install Packages
There are already ready-made packages in R for many operations. This can be seen in the example of the RStudio tutorial. If you call this via the tab “Tutorial”, some packages will be installed without further ado. Once all packages for the tutorial have been downloaded, the tutorial can be started in RStudio.
This procedure can generally be done for other packages in RStudio, but the packages can also be installed manually in the R console. For example, if you want to install the” tidyverse ” package, which can be used to process data, the following command is entered in the console:
install.packages("tidyverse")
To load the package, the following command is used:
library(tidyverse)
Packages can also be searched and loaded in RStudio. The Packages tab shows the available packages to view and offers a built-in search. The “Install” button installs a package, the “Update” button updates an already installed package.
Get Help in R
Since R is relatively complex, it may be difficult to remember all the necessary functions. On the “Help” tab you will find a detailed help for R. Here are also links to instructions on the Internet. The tab also has a search field that can be used to search specific terms directly.
Help can also be displayed in the console. To do this, either the command “help” or the character”?”, for example “help()” or “?(tidyr)“. The help is then also displayed on the “Help” tab in RStudio.
Create projects
RStudio works with” Projects”. A project contains not only the R code, but also all the necessary files. New projects can be created via the menu item “File”, or via the project menu item in the upper right corner of RStudio. Projects can also be opened or closed here to load another team project.
(ID:46834138)